Com cada vez mais abrangência e utilização em diversos setores, desde a recomendação de séries até a previsibilidade de doenças, as empresas dão cada vez mais valor ao uso de machine learning em suas operações. Nesse artigo discutiremos o futuro do machine learning e seu valor em diversos setores.
O uso de machine learning tem se tornado cada vez mais presente em nossas vidas diárias. Prevê-se que o mercado global de ml cresça aproximadamente 1.290% pelos próximos 8 anos.
Apesar de ser um tópico de tendência, o termo ‘aprendizagem de máquina’ é frequentemente usado de forma intercambiável com o conceito de machine learning. Na verdade, o aprendizado de máquina é um subcampo da inteligência artificial baseado em algoritmos que podem aprender com dados e tomar decisões com mínima ou nenhuma intervenção humana.
Muitas empresas já se anteciparam e começaram a utilizar algoritmos de ml em suas operações, devido ao seu potencial para fazer previsões e decisões de negócios mais precisos. Em 2020 foram arrecadados U$ 3.1 bilhões para empresas de machine learning. O uso dessa tecnologia pode trazer mudanças transformadoras em todos os setores.
Aqui estão algumas possíveis previsões para o futuro do machine learning no mundo:
A computação quântica pode definir o futuro do ml
A computação quântica permite o desempenho de operações simultâneas em múltiplos estados, permitindo assim, um processamento de dados muito mais rápido. Em 2019, o processador quântico Sycamore, utilizando um chip com 20 de seus qubits (unidade de informação quântica) executou uma tarefa que levaria 10.000 anos para ser concluída, em 200 segundos.
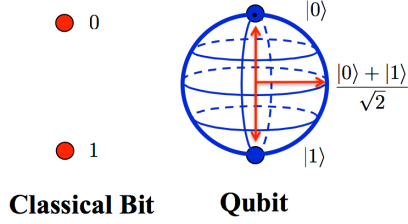
Para a computação quântica, não podemos utilizar a mesma forma de processamento e armazenamento de dados utilizado na computação clássica. É necessário o uso de uma unidade de informação diferente. Então para o lado quântico da força funcionar, originou-se da física quântica o qubit.
Ilustração da esfera de Bloch, representando um qubit:
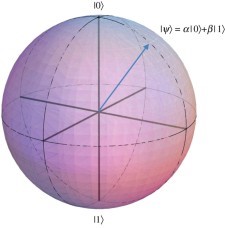
Indo para representação matemática, o qubit está associado a um estado bi-dimensional cuja base ortonormal é formada pelos vetores:
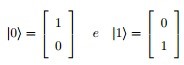
Assim, o espaço de estado associado ao qubit pode ser definido como: |?> = ?|0> + ?|1>. Onde, ? é um vetor unitário de uma combinação linear de ? e ? que, por sua vez, são números complexos normalizados (|?|² + |?|² = 1). Esses coeficientes definem e possibilitam o cálculo da amplitude de probabilidades do espaço de estado do qubit permitindo duas respostas possíveis em suas medições. Melhor dizendo, podemos medir a probabilidade dele ser 0 (P(0) = |?|²) ou 1 (P(1) = |?|²) . Assim, enquanto o bit clássico pode apenas ficar no estado 1 ou no estado 0. O qubit pode assumir os estados extremais 1 e 0 na base ortogonal e ambos ao mesmo tempo graças a variação de sua amplitude.
Hoje já é possível realizar simulações quânticas em arquiteturas multicore, com o uso de bibliotecas como a qgmc-analyzer.
Enfim..
Desse modo concluímos que machine learning pode ser utilizado para melhorar a precisão das operações e tomadas de decisões, executando testes automatizados com a finalidade de prever escolhas.
O AutoML irá facilitar o processo de desenvolvimento de modelos end-to-end
O AutoML está automatizando o processo de aplicação de algoritmos de aprendizado de máquina para concluir tarefas da vida real.
Além de tudo, o AutoML permite que um público mais amplo use o machine learning, o que indica seu potencial para mudar o cenário tecnológico. Aqui estão alguns estágios que o AutoML pode automatizar:
– Pré-processamento de dados (melhoria em qualidade e transformação de dados não-estruturados)
– Engenharia de recursos (algoritmos de aprendizado para ajudar a criar recursos adaptáveis)
– Extração de recursos (utilizar diferentes conjuntos de dados para produzir resultados que diminuirão o tamanho dos dados processados)
– Seleção de recursos (escolha de apenas recursos úteis para o processamento)
– Implantação e monitoramento (modelo implantado na estrutura, com monitoramento através de painéis)
Setores que devem se beneficiar bastante de ml:
O setor de saúde é um dos que geram uma vasta quantidade de dados. A aplicação de técnicas de machine learning pode contribuir para previsões e tratamentos clínicos.
– Previsões de doenças (com base no histórico familiar, laudos médicos passados e estatísticas em big data)
– Descoberta de drogas (coletando e observando padrões celulares)
– Registros eletrônicos de saúde (seleção de recursos úteis e inclusão nos dados de monitoramento)
O setor financeiro é um dos que serão grandemente impactados por machine learning nos próximos anos. No Brasil, podemos observar um mercado embrionário no uso de ml, mas que deverá ser bastante promissor pelos próximos anos.
A coleta de dados como (perfil de consumo, perfil financeiro, open banking, histórico de investimentos, etc..) pode ajudar na previsibilidade de potencial assinatura de produtos financeiros.
O Open Banking deve ser um dos divisores de água para ml pelos próximos anos, onde grandes instituições financeiras terão a possibilidade de se aproveitar da coleta de múltiplos dados dos clientes para aplicar algoritmos automatizados, com a finalidade de prever o comportamento do(a) cliente para cada produto existente.
Já é realidade que observamos movimentos globais de open banking, como o organizado recentemente pela CIBC, o National Australia Bank e o Grupo NarWest, onde foi anunciado o primeiro desafio global de open finance, contando com o apoio da Amazon Web Services (AWS).
Em Python, observamos diversas bibliotecas relacionadas ao tema (e já em uso), tais como:
– Numpy
– Scipy
– Scikit-learn
– Theano
– TensorFlow
– Keras
– PyTorch
– Pandas
– Matplotlib
Entre outras..
No fim, o que esperamos dessa tecnologia para o futuro é ter a possibilidade de consumir grandes pilhas de dados não-estruturados/não-relacionais, e obter destes os resultados para possíveis escolhas, de maneira intuitiva, rápida e eficiente.
E desse modo, iniciamos uma nova etapa valiosa na era do processamento e consumo de dados.
Autor:
Eric Vinicius de Oliveira Rocha

Excelente artigo, e o futuro está cada vez mais conectado a inteligência artificial, e tudo tende a evoluir para este caminho.